
Cursor & GPT-5 took over our newsletter!
Skewed joins are quiet cost multipliers. One hot key creates massive shuffle imbalance, long-tail tasks, and 2–5x cost. Here's how to fix it.

Hey there,
So we're experimenting with GPT-5 for this week's newsletter. Jury's still out, but here's what it cooked up for you...
The problem that's probably burning your budget right now
You know that feeling when one Spark job takes 3x longer than it should? Nine times out of ten, it's skewed joins. Some hot key (anonymous users, null tenant IDs, that one power user with 10M events) creates a few massive shuffle partitions while the rest of your cluster sits there twiddling its thumbs.
I see this constantly in r/dataengineering threads. "Why is my job so slow?" Usually it's join skew torching their AWS bill.
Here's the copy-paste fix
The setup that's probably familiar:
from pyspark.sql import functions as F
# This looks innocent enough...
events = spark.table("fact_events") # 100M rows
users = spark.table("dim_users") # 1M rows
# But user_id has that one enterprise customer with 20% of all events
joined = events.join(users, "user_id", "left")Step 1: Turn on the good stuff (AQE)
# These should honestly be defaults by now
spark.conf.set("spark.sql.adaptive.enabled", "true")
spark.conf.set("spark.sql.adaptive.skewJoin.enabled", "true")
spark.conf.set("spark.sql.adaptive.skewJoin.skewedPartitionRowCountThreshold", 250000)
spark.conf.set("spark.sql.adaptive.skewJoin.skewedPartitionThresholdInBytes", 268435456) # 256MB
# Now run the same join - AQE will split those massive partitions
joined = events.join(users, "user_id", "left")Step 2: Broadcast the small side (if it actually IS small)
# Rule of thumb: if your dimension is < 500MB after filters, broadcast it
joined = events.join(users.hint("BROADCAST"), "user_id", "left")Step 3: For the really stubborn cases - salting
# When you have that one customer that's just... massive
HOT_CUSTOMER_ID = 42 # Replace with your actual hot key
SALT_BUCKETS = 16
events_salted = (events
.withColumn("salt",
F.when(F.col("user_id") == HOT_CUSTOMER_ID,
(F.rand() * SALT_BUCKETS).cast("int"))
.otherwise(F.lit(0))))
users_salted = (users
.withColumn("salt",
F.when(F.col("user_id") == HOT_CUSTOMER_ID,
F.sequence(F.lit(0), F.lit(SALT_BUCKETS-1)))
.otherwise(F.array(F.lit(0))))
.withColumn("salt", F.explode("salt")))
# Join on both user_id AND salt
joined = events_salted.join(users_salted, ["user_id", "salt"], "left")
# Drop the salt column downstream - it's just a technical detailHow to spot this in the wild
Spark UI red flags:
Stage timeline looks like a hockey stick (most tasks finish fast, a few stragglers kill you)
Shuffle read size distribution is all over the place
One executor is pegged while others are idle
Quick diagnostic:
# Always run this before big joins
events.groupBy("user_id").count().orderBy(F.desc("count")).show(20, False)If the top row has 10x more records than the second row, you've got skew.
If you're using Snowflake/BigQuery instead
Snowflake:
-- Force broadcast with hints
SELECT /*+ BROADCAST(users) */
events.user_id,
SUM(events.amount)
FROM events
JOIN users ON events.user_id = users.user_id
WHERE events.event_date >= CURRENT_DATE - 7
GROUP BY 1;BigQuery:
Cluster your large tables by join keys
Use partitioning aggressively to limit scanned bytes
Pre-aggregate when possible
The real talk
Look, skewed joins are everywhere. That anonymous user ID, deleted records with NULL foreign keys, your biggest enterprise customer - they all create hot partitions. AQE helps, but sometimes you need to get your hands dirty with salting.
The good news? Once you fix it, it stays fixed.
Human here, let us know how much our experiment has succeeded in comments. We’ll love to test more!
Now, onto the other things:
Launching e6data’s Hybrid Data Lakehouse: 10x Faster Queries, Near-Zero Egress, Sub-Second Latency
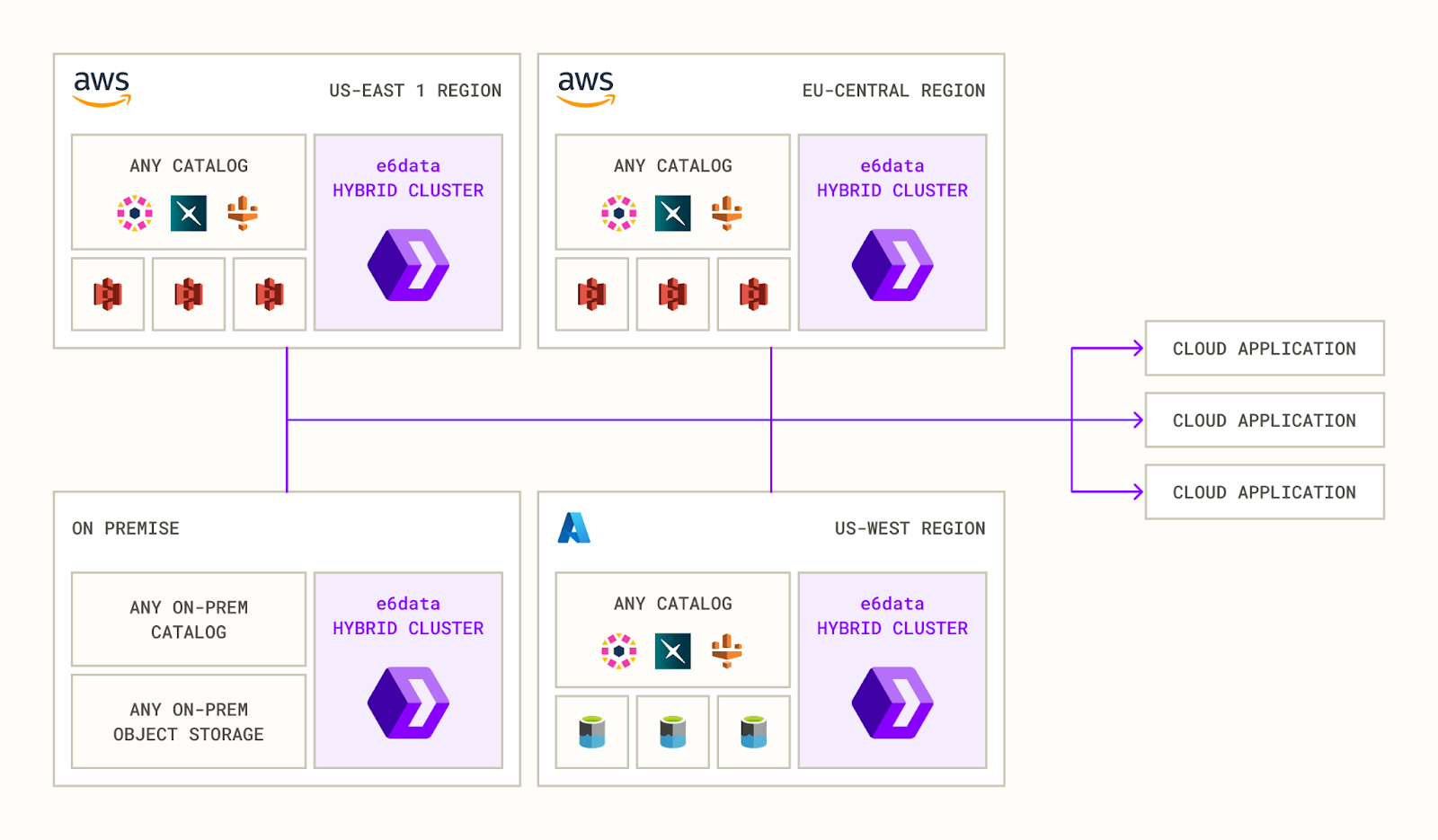
Most enterprises today deal with high egress costs, governance issues, migration, and latency issues in hybrid lakehouses due to their fundamental architectural limitations.
We are solving this with our federated SQL engine + hybrid cluster architecture. The architecture is designed such that the hybrid cluster is abstracted out from the end user's querying experience, and they get to write queries as though there were a single cluster talking to all these data sources.
Used in production by customers, the latest benchmarks on e6data’s hybrid data lakehouse deployment are as follows:
10x speed by keeping compute local.
~0% egress fees
Adding cache reduces another ~40% off latency with no extra data movement.
For more details, benchmark setup, case study, product feature and docs, refer to this page!
Community & Events
