
Spark’s Crossroads, Polars Momentum, and YouTube’s Guardrails for Petabytes
Your weekly sweep of top 3 trends and hacks in data engineering by leading tech companies a peek at what we’re building at e6data.


🔥“Spark Is the New Hadoop” — or Is It?
A widely shared post argues we’ve reached peak Spark: JVM GC pain, sluggish startup, and the rise of Rust/C++ query engines (Photon, DataFusion + Comet, Velox, Daft) point to a future with lighter, Arrow‑native back‑ends. Critics counter that Spark’s API and rich ecosystem—not its engine—are the real stickiness, and drop‑in Rust/C++ cores may keep it alive.
Takeaway: Decouple APIs from engines and keep an eye on emerging Rust projects before declaring Spark “dead.”
▶️ YouTube‑Scale Guardrails
Decades in, YouTube still breaks the curve: 20 million videos are uploaded per day, 20 billion videos are stored, and 3.5 billion daily likes.
At that size, a forgotten SELECT * or rogue cluster can cost millions. Therefore, the data infra team enforces automated guardrails:
Mandatory partitions (upload_date or shard_id)
Query cost alerts ≥ $1,000
“Design for safe failure”, so teams accidentally don’t melt the budget
🐻 Polars & the “Goldilocks” Zone
Early adopters report 5–7x speed‑ups (and ~80 % cost cuts) by replacing PySpark jobs with Rust‑based Polars on a single r6g.8xlarge. Key features:
Lazy execution by default
Full threading on Arrow columns
Upcoming distributed mode via Ray
Optional GPU acceleration through RAPIDS
Expect Polars + Iceberg to gobble the 10 GB to 1 TB jobs that don’t justify a full cluster.
We are working on something cool too! (land and query event data in <15 seconds)
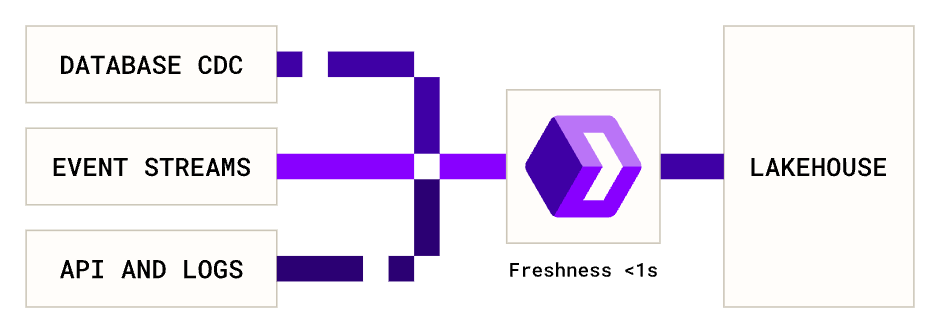
We’re drinking our own Kool-aid at e6data: the team is working on a new product offering that lands Kafka (and soon CDC) streams directly into your lakehouse and makes them queryable in sub-second latency—no Flink clusters, no real-time OLAP database, no data shuffles. This can help reduce time-to-insight by 95%, and relieve some of that infrastructure headache. Look for native CDC support and mobile-SDK ingestion in v2 next quarter.
Early‑access ➡️ Book a 15‑min walkthrough
Fresh From the Team
Podcast: Decoding e6data’s Architecture – our Head of Engineering with Pete Soderling, Zero Prime (listen)
Blog: Why Catalogs Matter – the Book‑keeping of Apache Iceberg (read)
Tech Note: Eliminating Redundant Computations with Automatic CTE Detection (read)
Meet Us on the Road

We are at the Snowflake Summit, Databricks’ Data + AI Summit 2025, and the Gartner Summit this month. Here’s what’s going down:
Vishnu is taking the stage at the Data + AI Summit to present how e6data can help deploy your data platform (like Databricks) to any environment: cloud, on-prem, or hybrid.
The engineering team is demoing our real-time streaming ingest to the world at our booths at both the Summits
Giveaway: Enter to win limited‑edition Star Wars LEGO® sets
Lakehouse Days Community
We just crossed 1,100 members from teams like Netflix, Uber, and Meta. Next meetup: June 21 —add the calendar to get first dibs. Subscribe to our YouTube channel for previous session recordings.
Thanks for reading—see you next month! 🚀