
Embeddings Exposed, Kafka in 300 Lines, Redundant SQL, and Lakehouse Costs Breakdown
Deep dives into vectors, minimalist Kafka builds, primary keys, SQL as a language, and transparent lakehouse pricing,


🔬 How to make Vector Embeddings?
An interactive Hugging Face Space peels back the 1,536-D token matrix of DeepSeek-R1-Distill-Qwen-1.5B, letting you poke real vectors with cosine-similarity tools.
Dissects static token vectors vs contextual hidden-state embeddings, clarifying why only the first layer stays fixed while deeper layers mutate with self-attention.
Code shows how
torch.nn.Embeddingis lifted, cached, and queried in milliseconds—then usestorch.topkon cosine scores to map local neighbourhoods.Notebook prints raw rows: e.g. the token "HTML" expands to a 1,536-float vector, proving verbatim that the model’s dictionary sits in RAM not VRAM.
🛠️ Kafka Core in ~300 LOC of Python
A Redditor rewrites Kafka’s 2011 design in pure Python: single-threaded broker, producers, consumers, offset tracking, no ZooKeeper, no partitions.
Append-only log + pull-based consumer loop illustrate back-pressure mechanics.
Community calls out the missing bits: partitioning, segment compaction, persistence, concurrency-safety.
Author plans to add partitions next; goal is architectural clarity, not prod-grade throughput.
Our Takeaway: Re-implementing the log-structured core is the fastest way to grok why sequential disk I/O + monotonic offsets scale.
🔑 Primary Keys vs Petabytes: When Constraints Bite Back
Another Reddit thread debates surrogate hashes & GUIDs versus brute-force uniqueness checks.
Surrogate keys (MD5/UUID) enable SCD2 change tracking while decoupling from source schemas.
One team’s 5.7 trillion-row sensor fact grew its 8-byte PK index to 45 TB uncompressed- sometimes the index is the data.
Others drop keys on ultra-wide fact tables, trading insert speed for read-time de-duplication.
Our Takeaway: Keys are good insurance until the index dwarfs payload, then explore late-binding dedupe or zone maps.
🗑️ SQL Spec Gripes: MERGE, RIGHT JOIN & Recursive Rumbles
A Reddit rant blacklists MERGE, recursive CTEs, and RIGHT JOIN, sparking a highly heated debate.
OP slams non-idempotent
MERGE, “clever” recursive CTEs, and unreadable RIGHT JOINsVeterans defend recursive CTEs for graph traversals; say RIGHT JOIN is merely rare, not wrong
Tangent: BigQuery’s new pipe operator (
|>) pitched as a saner logical-order alternative
Our Takeaway: A disciplined, cross-engine SQL subset—plus pipeline syntax—beats holy wars over edge-case clauses.
💡 Cost Calculator: Instantly Price Your Lakehouse
We’re launching an interactive Cost Calculator that shows what you’ll spend on e6data versus legacy engines, before you deploy.
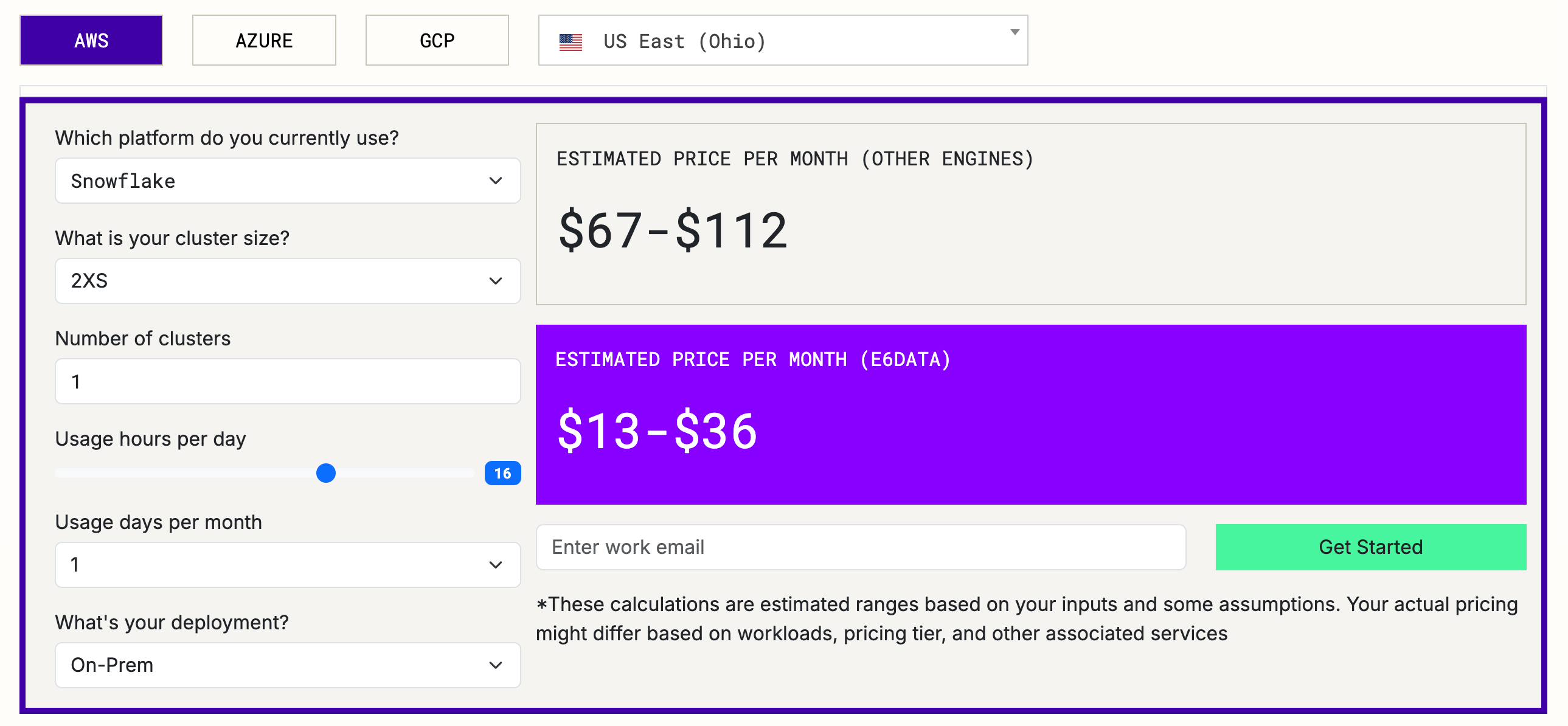
Estimates query costs on your lakehouse platform in < 1 min.
Pick cloud (AWS, Azure, GCP), region, cluster size, hours/day, and see side-by-side monthly totals in seconds.
Community & Events
Lakehouse Days Replay – Missed our “From Stream to Lakehouse” session? Catch the full recording on e6data’s YouTube.
Blog Series – Building a Modern Data Pipeline in Snowflake: From Snowpipe to Managed Iceberg Tables with Sync Checks — deep dive from our engineering team (Part 1 out now).
Hiring – We’re growing! Explore open engineering roles → here