
Deep-Fake Interviews, ETL Bottlenecks, and Shift-Left Showdowns
Your weekly sweep of top 3 trends and hacks in data engineering by leading tech companies a peek at what we’re building at e6data.


🤖 Deep-Fake Devs: Well, this could have been a sitcom episode
Recently, a hiring manager spent 30 minutes interviewing a deepfake AI bot (as a data engineer), AND the internet is hilarious about it.
Redditors point out their irony: HR wanted algorithms to pick humans, so now algorithms are applying for the jobs. Since ATS filters let bot-written CVs sail through (thanks to tools like Jobscan, HyperWrite’s Resume Aligner), real engineers suffered at times. Give the entire thread a read here.
Takeaway: The HR industry for tech hiring is (and will more and more) adding checks like live‑coding, camera checks, put your hand in front of your face, or “tell me five facts about X, unrelated to engineering”‑style prompts to help things get better.
⚙️ Modern ETL is all about living up to modern software deployment principles
In yet another ETL rant, a Reddit user claimed that an Oracle migration to dbt went wrong from one stored procedure to hundreds of models, stretching runtime from 1 hour to 4 hours. The community notes that dbt’s strength is testable, incremental ETL, not raw speed, and that each model incurs orchestration overhead, and Oracle’s optimizer prefers fatter queries.
Takeaway: Power users fix it by materialising large views, batching models, or shifting heavy lifts to Spark/Python.
🛡️ Shift Left or Shift Blame?
Reddit is split on yet again or whether this is an actual trend or just another marketing gimmick: “start right” (spray downstream observability) then “shift left” (convert findings into upstream data contracts).
Some people argue it is the latter, while few give examples like- If a dashboard user spots bad numbers, you trace the issue back to the raw data and repair it there. That single upstream fix saves every downstream report, not just the one someone complained about. Which is why shift left is more of a stronger detection and prevention strategy.
Takeaway: Choose your battles depending on your scale. Meanwhile, vendors already sell both ends of the funnel.
We’re fixing multi-cloud pain, too — query data wherever it sits
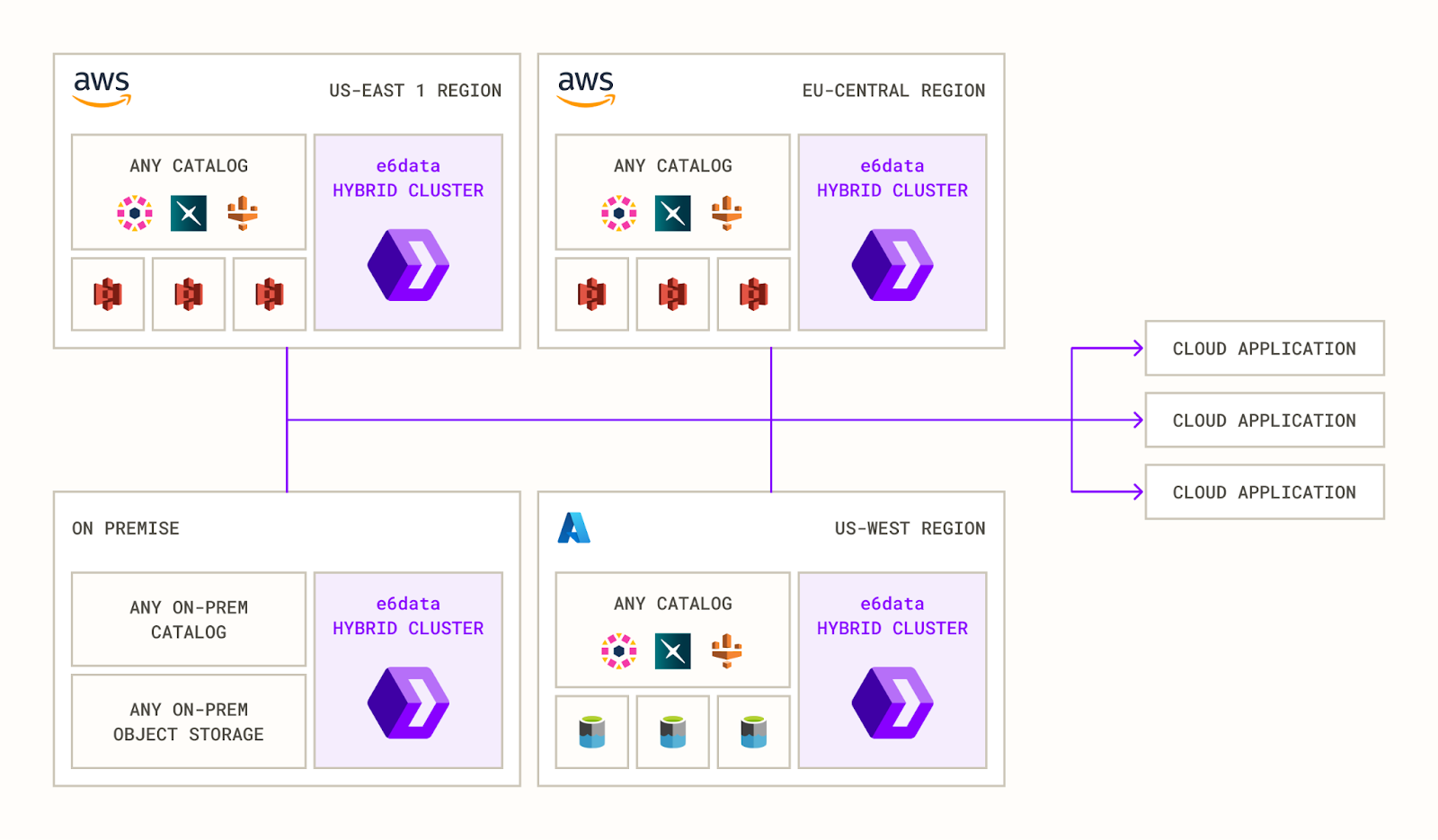
We’re sipping our own Kool-Aid at e6data: Hybrid Lakehouse lets you drop a single, location-aware cluster next to every storage bucket—on-prem, AWS, or “that other cloud.” Compute stays put, so nothing mixes across regions, cutting egress fees by up to 99% and keeping every table compliant and governed.
With affinity-aware execution and streaming ingest baked in, dashboards light up in sub-minute latency—no duplicate copies, no forklift migrations, and zero ACL drift.
Spin up a hybrid cluster? ➡️ Book a 15-min walkthrough
Some cool stories from our team:
Vector Search on S3 through SQL- breaking down e6data’s ability to query unstructured data
Solving Geospatial Analytics Performance Bottleneck: H3 vs Quadkey: Unlocking geospatial analytics in production at scale
Hive Metastore as an Apache Iceberg Catalog: moving pieces, end-to-end setup, locking, and concurrency quirks
Meet us on the Road

We had fun at the Data + AI Summit, Snowflake Summit, and AWS Summit this week. Here’s what’s went down:
Vishnu took the stage at the Data + AI Summit showing how e6data lifts your lakehouse to any environment—cloud, on-prem, or hybrid.
Bharath, our Head of Product, took the stage at the AWS Summit to present how e6data powers vector search.
We exchanged ideas with a mountain of cutting-edge teams, stocking the team’s calendar with months of interesting conversations.
Also, the Lakehouse Days community has officially 1200 members and counting from top engineering teams like Netflix, Uber, Meta, and more. We are hosting the next one on July 12th in Bangalore, subscribe to the calendar for the first updates!