
Agent-Built JUnit Suites, CDC vs Daily Snapshots, Ducklake vs Iceberg, Queries, Costs, and more
Every Friday, we deliver your weekend win: copy-paste tutorial, cost-optimisation technique, CFPs worth your pitch, and fresh ideas from the field. Stop surfing fluff.


🔧 We used a few agents to bring in JUNit runner support for regression run, it sort of worked?
An engineer from our team pointed IntelliJ’s Junie agent (Claude 3.7 under the hood) at a hand-rolled regression harness (~2000 SQL queries) and asked it to surface each query as an IDE-runnable JUnit test. Here is what went down:
Agent #1 — Junie + JUnit 4 reflection adapter. A single prompt asked Junie (IntelliJ’s Claude-powered agent) to analyse
RegressionTest.runTestsand emit an adapter that registers every query as a JUnit test. Junie delivered code that works, but hangs on brittle reflection hooks and produces hash-based test names with no Run/Debug actions.Agent #1, retry — JUnit 5 Parameterized / Dynamic tests. After nudging Junie toward Jupiter, it rewrote the runner, solving the name issue but introducing new ones: incremental discovery kept appending tests mid-run; only ~70 % of the 2006 tests were detected, and per-test stdout/stderr never reached the console.
Edge-cases that still bite.
IDE agent loops on feedback instead of asking for help.
Environment variables (default schema, storage endpoint) are ignored, so failed tests hit remote buckets.
Our Takeaway: IDE agents can scaffold a runner in minutes, but deep plumbing—stable discovery, clean logs, env-aware execution—still needs a human who knows JUnit extension points. Treat today’s agents as junior devs: great at boilerplate, lost in integration hell.

🔄 CDC vs. Daily Snapshots?
Data engineers on Reddit recently argued (and sort of concluded) that CDC is cheaper, safer and more granular than nightly full snapshots:
Pulling changes straight from the DB WAL avoids table locks and SELECT * hell.
Real-time extraction doesn’t force real-time delivery—buffer it rather then landing hourly or daily.
For 100M+ rows tables, daily snapshots hammer network & compute; Debezium-style CDC streams are faster.
Our Takeaway: Unless your tables are tiny, CDC + append-only logs win on both cost and correctness, while still letting teams materialize snapshot views whenever they like.
🦆 DuckLake vs. Iceberg — Metadata Wars (Again?)
r/dataengineering is hot with another metadata war this week:
One-binary catalog. DuckLake boots from a single DuckDB file; you’re querying with plain SQL in minutes, no Hive metastore, no Spark session spin-up.
Adoption hurdle. Redditors call it a “pure improvement” over Iceberg but say they’ll jump only after Spark / Trino / Flink connectors and real petabyte tests—land.
Could just fold in. Even Iceberg fans note its catalog is already pluggable; a SQL-backed option like DuckLake might slip upstream instead of forking the ecosystem.
Our Takeaway: The fight isn’t about table files but about where metadata lives. We will watch out for connector support: once the major engines speak DuckLake, JSON catalogs might become legacy.
💡 We’re cooking up a Query & Cost Optimization Hub
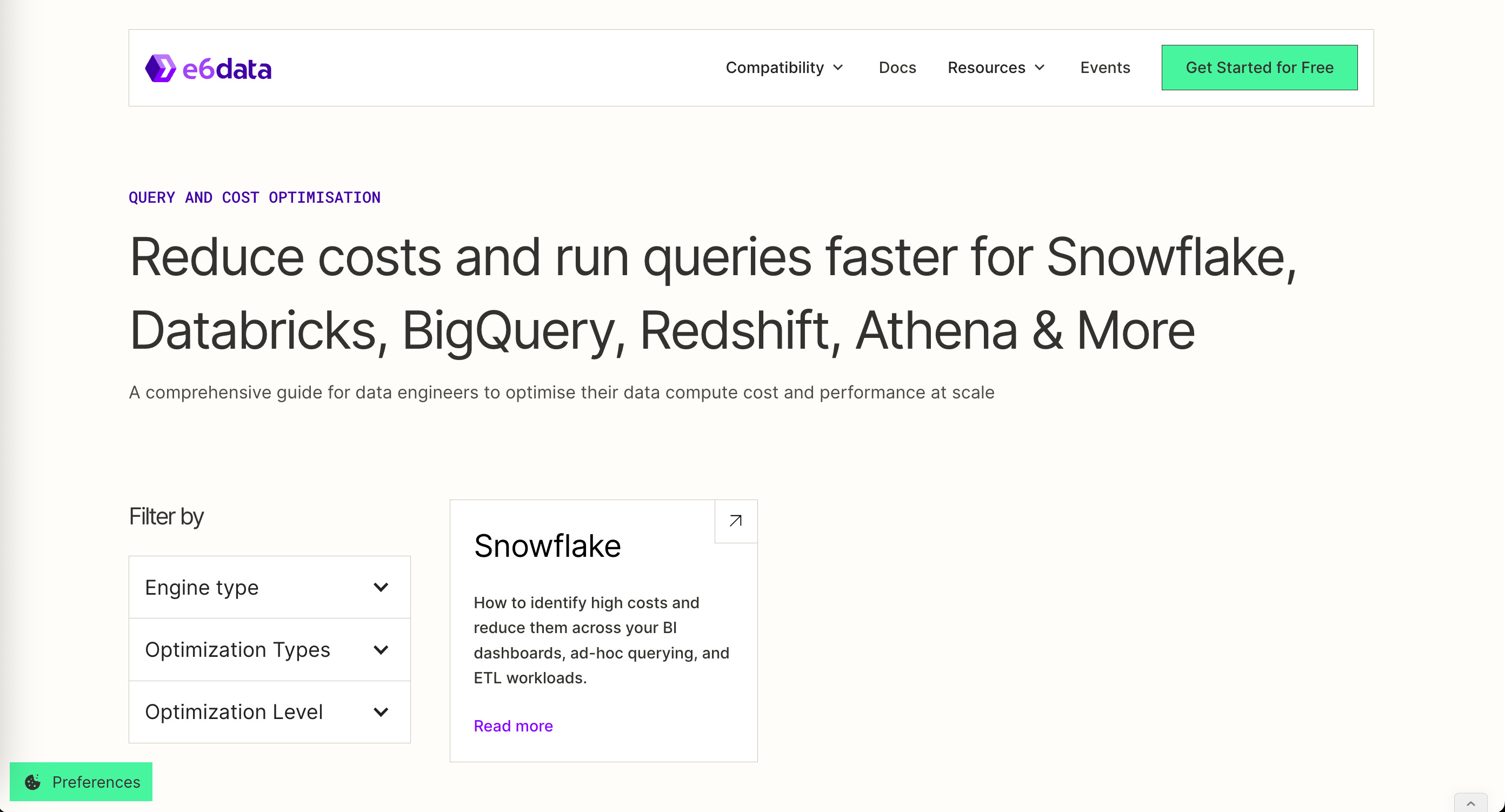
We’re launching: a hub which distills cost-optimising and latency-crushing playbooks
One for or every major compute engine—Snowflake, Databricks, BigQuery, Redshift, Athena, ClickHouse, Fabric, Starburst, and more.
Filter by engine, choose “query” or “cost” mode, and grab beginner-to-advanced tactics.
First one is out with Snowflake Cost Optimisation for Beginners, rest to follow soon.
